All About Programming Languages
- Arpan Mahanty
- May 13, 2022
- 4 min read

Introduction
Our engineers have been building programming languages since the Dark Ages of computing. Thousands of them have been created, and more are being created every year, but the way we build programming languages is virtually unchanged, though today’s machines are literally a million times faster and have more storage in orders of magnitude.
So, I started wondering how such a simple thing as a raw source text, which is literally just string of characters can be understood and executed by a machine which only understands simple CPU instructions in form of 0’s and 1’s.
We can visualize the whole, as a network of paths climbing a mountain. It literally starts with a simple raw source text and in each phase, we analyze the program and transform it to some higher-level representation where the semantics (meaning) become more apparent.
As we gradually reach the peek of the mountain, we can see what the users code means. As we continue our journey to the other side of the mountain, we transform this highest-level representation down to successively lower-level forms to get closer and closer to something we know as CPU instructions.
Let’s start our journey we a bare text of user’s code.
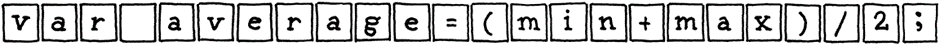
Scanning
This marks the first step of our journey. Scanning also known as lexing, or lexical analysis is the process of tokenizing the linear stream of characters into a series of something more akin to “words”, in other words known as tokens. Non-meaningful characters like whitespaces or comments are often filtered out during this step, leaving behind a clean sequence of meaningful tokens.

Parsing
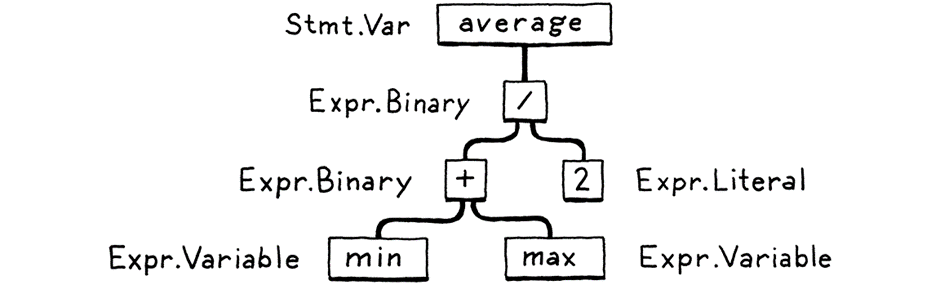
This step is the most important step in the construction of a programming language, as because it addresses the syntactical nature of a programming language. A parser generally takes the flat sequence of tokens and builds a tree structure also known as parse tree or abstract syntax tree.
Static Analysis
This step is often performed to analyze the syntax tree to build some more information from it as well as often used to check for things like variable declaration scope depth and type safety, which is generally not assessed during the parsing phase. For example, in a simple expression like a+b, we know we are adding a and b, but we don’t know what those names refer to. Are they local variables? Global? or where are they defined?
The first bit of analysis that is most used by the languages is called binding or resolution. For each identifier, we find out where that name is defined and wire the two together. This is where scope comes into play i.e., the region of source code where a certain name can be used to refer to a certain declaration.
If the language is statically typed, this is where we do type checking. Once we know where a and b are declared, we can also figure out their types. Then if those types don’t support being added to each other, we report a type error.
Optimization
As now we understood the actual meaning of the user’s source, we are free to swap it out with a different program that has the same semantics but implements them more efficiently, in other words we can optimize it.
For an example, let’s consider the user typed in the following snippet
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
we could do the calculation in the compiling phase and change the above snippet to something like
pennyArea = 0.4417860938;
Thus, the optimization step plays an important role in any programming language business.
Code Generation
The last phase of our journey is to convert into a form that the machine can run. In other words, generating code (or code gen), where “code” usually refers to the kind of primitive assembly-like instructions a CPU runs and not the kind of “source code” a human might want to read.
The final generated code can belong to either of the two forms –
CPU Instruction – It is the real chip’s language that the OS can load directly onto the chip. Native code is lightning fast, but generating it is a lot of work. It also means your compiler is tied to a specific architecture i.e., if your compiler targets x86 machine code, it’s not going to run on an ARM device, and vice versa.
Bytecode – To solve the above problem, we produced code for a hypothetical, idealized machine, instead of instructions for some real chip. These instructions are generally known as bytecode because each of these is often a single byte long.
Finally, if our compiler produces bytecode, it become the work of the Virtual Machines installed in the executing machine to convert it into native machine code, to be loaded directly into the chip by the OS.
Runtime
The final work in our journey is to execute the program. This can be done by simply telling the operating system to load the executable and finally executing it. It also consists of some services that our language provides while the program is running. For an example, if the language automatically manages memory, we need a garbage collector going in order to reclaim unused bits.
All these things are generally done in the executing time, so we often call these as runtime. Generally, in a fully compiled language, the code implementing the runtime gets inserted directly into the resulting executable or if the language is run inside an interpreter or VM, then the runtime lives there inside of the VM.
Conclusion
Through this journey we learnt how a simple raw source text is converted into more complicated meaningful structed form and finally converted it into something simpler which can be easily read by the machine, by a step-by-step mechanism developed by years of hard work by our engineers, whose fruit is now available as a fast and efficient environment running in the background of every software we use for our daily needs.
Comments